以Spring作为起点,闲聊一下。
没多久前,SpringBoot 2.0里程碑版发布了,作为一个JavaEE程序员,这是大事件。从Spring到SpringBoot再到SpringCloud,个人理解,Spring提供了程序的解决方案,SpringBoot不仅仅提供了方案而且还把过程简化了,而且很多地方达到了升华的地步(比如容器内置化),SpringCloud呢?则提供了全套方案,从业务处理,原生分布式,容灾,再到大数据处理,再到持续集成,可以说一个产品的生命周期,Spring已经做到了90%(个人理解),国内暂时应该没有达到这个程度,迭代很快,而且是“多线程”的,多个方向同时快速迭代(多个项目)。
SpringCloud想干啥?真正的全家桶!感谢Spring,感谢后面默默编码的人,还有,感谢伟大的Apache!有点扯远了,我们赶紧扯回来。还是说说标题上那个东西吧,HTTP/2,因为SpringBoot2.0开始支持HTTP/2了。
因为自己并不专业,所以尽量用一些不专业的词汇去‘扯’,其实更像是翻译(https://http2.github.io/),出错的地方,希望指正,我会以出BUG的心态去应对。
既然说HTTP/2(为什么不写成HTTP2.0?后续说),那当然要说HTTP/1.0。
HTTP/1.1已经为Web服务了15年以上,它的问题也随着时间的推移开始暴露。最关键的问题就是,它每个请求都需要发出一次TCP,虽然可以并行请求,但依然导致了资源的浪费,而且服务器负担也要是考虑的重要因素。如果用Java程序猿的思维去理解的话,每次新建对象都是通过new操作,这明显不是我们想要的,我们更想复用TCP。
也就是说,HTTP/2产生的最根本原因是因为HTTP/1.1开销太大了,优化性能,同时再来点新特性,比如安全性。下图是HTTP/1.1请求网页的截图:
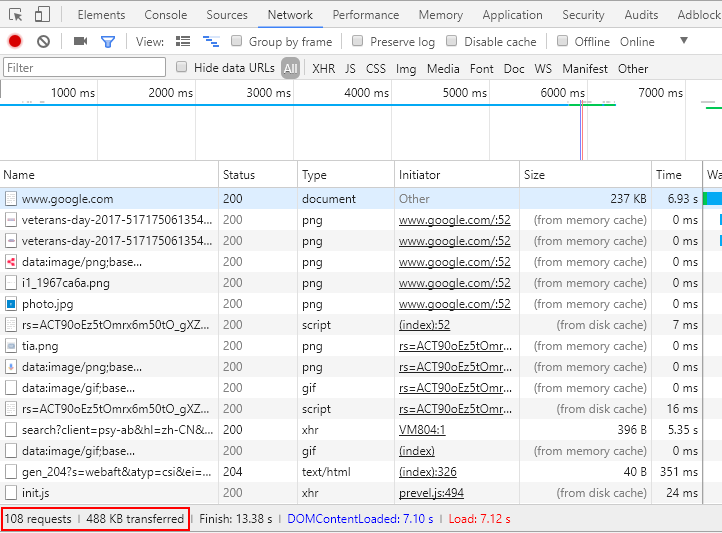
通过上图我们得知,虽然我们只获取到了488KB的数据,但却足足发送了108个请求,现阶段,我们会将某些静态资源通过合并的方式去优化(比如合并图片合并JS),但,终究不是我们想要的完美方案,就类似我们做数据库切分,虽然能够在程序里面去操作,但我们还是希望通过数据库中间件去处理,或者,直接使用分布式数据库(比如Google的Spanner,HBase等),比喻好像有点不太恰当。
正式开始HTTP/2的篇章吧!
HTTP/2是谁做的?主要是 和,他们主要是由HTTP协议真正实现者、用户、网络运营商以及HTTP专家组组成。同时由W3C跟踪最新进展,当然,也只是跟踪和维护邮件列表,并不参与其它工作。参与者大概是:Chrome、Firefox、Twitter、微软、Curl、Akamai等大公司,以及开发语言的HTTP实现者,比如Python、Java、Ruby、NodeJS之类的,。
因为是Java程序猿,所以单独说下哪些Java项目或产品正在跟进:
SPDY和HTTP/2?选择哪个?Google 2015年已经放弃SPDY,而且SPDY的核心开发也参与到HTTP/2中,所以,不用再明说了。
为什么叫HTTP/2而不是HTTP/2.0?官方说法大概是:在HTTP/1.X时代,因为因为这个小数点造成了太多混淆(误会),HTTP版本更想体现在兼容性方便,而不是新特性(有点似懂非懂的)。
和HTTP/1.X的主要区别:
1.HTTP/2是二进制传输,不再是文本传输。
意味着效率更高,错误率也更低。同时二进制能够将一些不规范的东西规范化。
2.请求将会复用,而不再是有序阻塞,可以用一个请求进行并行处理。
虽然HTTP/1.X通过’head-of-line blocking‘解决了部分问题,但并没有根本解决。
3.使用header压缩来减少数据量
这个好像没啥好多的,同一网页,太多资源的Header除了URL路径不同,其它几乎一模一样。
4.允许服务器将response主动推送到客户端。
现阶段,我们打开HTML,浏览器获取DOM,然后浏览器根据DOM中的资源链接再去请求资源。而主动推送的方式,就会出现这种场景,当你请求index.html的时候,服务器知道这张网页需要那些资源,没有等浏览器主动请求JS或者其它静态资源,服务器就已经主动往浏览器推送了,双刃剑。